Unlocking evidence from evaluation reports
Organisations commission thousands of evaluations every year, yet the evidence largely goes unread. EvalExplorer turns evaluation documents into searchable, queryable knowledge — so you can ask questions across hundreds of reports and get synthesised answers linked straight back to the source.
initial FCDO evaluations processed
evaluations at scale
cheaper portfolio queries
of structured extraction
Evidence that goes unused
A programme designer wanting to learn from past evaluations has two choices: spend weeks reviewing relevant reports, or decide on whatever knowledge is already at hand. Time pressure means the second usually wins.
Reading 200 evaluations to answer a single strategic question isn't feasible — yet that's exactly what portfolio-level learning requires.
Scale and cost
Even a large context window fits maybe a dozen full reports at once — not the hundreds a portfolio question spans. Feeding them in one at a time is slow, and the cost multiplies with every query.
Discoverability
ChatGPT and Copilot answer the question you ask, about the documents you hand them. They can't tell you which of 200 evaluations matter for your question — or surface the findings you didn't know to look for.
Shallow retrieval
A 150-page evaluation is mostly contents, annexes and terms of reference — perhaps 30–40 pages of real analysis. Vanilla RAG matches on surface similarity, returning loosely related passages rather than the reasoned evidence a question actually needs.
Synthesis limits
General tools analyse one document well and compare a handful adequately — but they can't surface recurring findings across a portfolio of hundreds.
We need portfolio-scale intelligence, not document-by-document chat or naive retrieval.
Invest once in extraction. Benefit at every query.
Evaluation reports have predictable structure — an Executive Summary summarises, a Findings section contains findings. Rather than processing whole documents at query time, we extract and structure their content upfront, at three increasing levels of granularity.
Each report is classified as a whole — evaluation type, geographic scope, thematic areas, methodology. Enables filtering like “all impact evaluations in Sub-Saharan Africa.”
Sections are extracted and normalised to a consistent taxonomy — “Results”, “Findings” and “Key Outcomes” all map to one category, so targeted retrieval returns complete sections.
Individual findings, recommendations and evidence gaps — each tagged with theme, country and region, and methodology, so you can ask for “sustainability findings from education evaluations in East Africa.”
Instead of querying 200 full documents, you query 50 relevant findings already filtered of noise. That cuts query cost 50–100× while improving precision — and enables analysis that “upload and ask” tools simply can't perform.
A workspace for portfolio-scale analysis
Browse, search and curate evaluations, then synthesise across them — with every claim traceable to its source. The analysis layer is operational and has been through multiple rounds of user testing with evaluation experts and external partners.
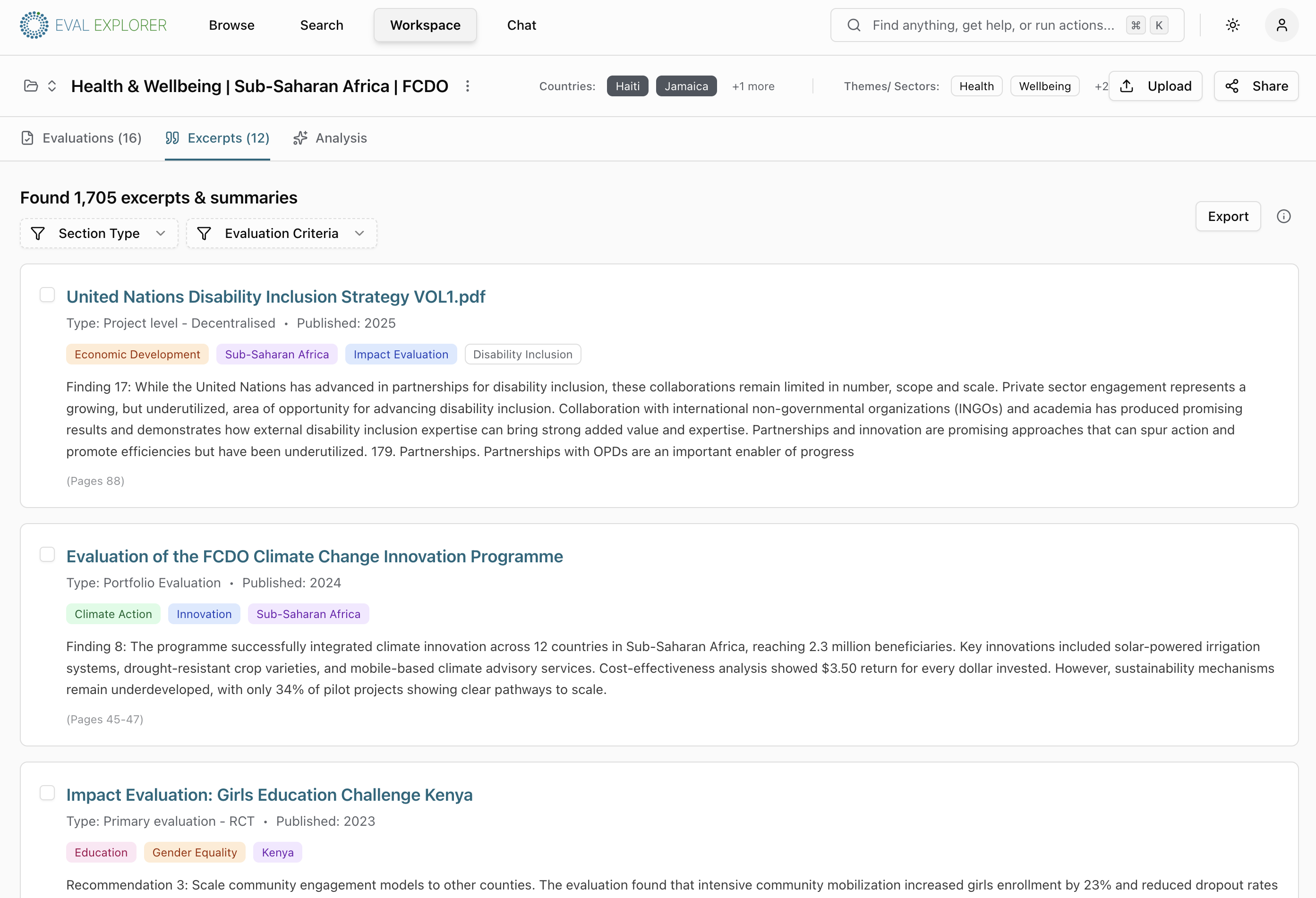
Browse
Discover evaluations through a visual evidence gap map. Switch axes — theme × region, type × country — and watch counts update as you filter to see where evidence clusters and where gaps remain.
Search
Hybrid keyword + semantic retrieval across full documents or extracted excerpts. Filters for theme, region, country, type and methodology persist across tabs, with counts that update dynamically.
Workspaces
Build curated sets of evaluations and share them with collaborators as editors or viewers. Each workspace keeps an audit trail of changes.
Excerpts
Extracted findings, recommendations and observations — each showing its source document, section, taxonomy tags and page references. Exclude irrelevant excerpts before you analyse.
Chat
Ask questions conversationally across the corpus. Every tool call is transparent — you see the search queries it ran — and answers carry the same inline source citations as the structured analyses.
Quality signals
Evaluation quality ratings and automated document quality flags let you weight or restrict analyses to higher-quality evidence.
Structured analysis, not just chat
Every analysis type supports per-run document selection and traces each claim to numbered source excerpts. Outputs export to PDF and Word, or publish to a read-only URL.
Summarisation
Thematic summaries across a collection, with numbered references linking every claim to its source excerpt.
Comparative
Compare findings across regions, time periods or intervention types — surfacing patterns and contradictions.
Temporal
See how evidence has evolved over time, rendered as a chronological timeline of understanding.
Custom queries
Expose the underlying prompt and write your own analytical question against workspace excerpts.
Data connector
Everything EvalExplorer does through the interface, available headless. We're building a connector layer that exposes our curated, domain-aware evaluation data system directly — so your own agents, chatbots and internal tools can tap into it without anyone touching the UI. Inherit the curation, extraction and analysis work we've already done, and build it into your own products.
MCP access
Connect any MCP-compatible client — Claude, ChatGPT, Copilot, or your own custom agents — to EvalExplorer's tools and curated corpus over the Model Context Protocol.
API access
A programmatic interface to search, retrieve traceable excerpts and run structured analyses — the same operations the workspace uses, callable from your own stack.
Agent access
Agent-ready endpoints let your internal agents query, synthesise and cite across the portfolio — inheriting our domain-aware extraction and source traceability.
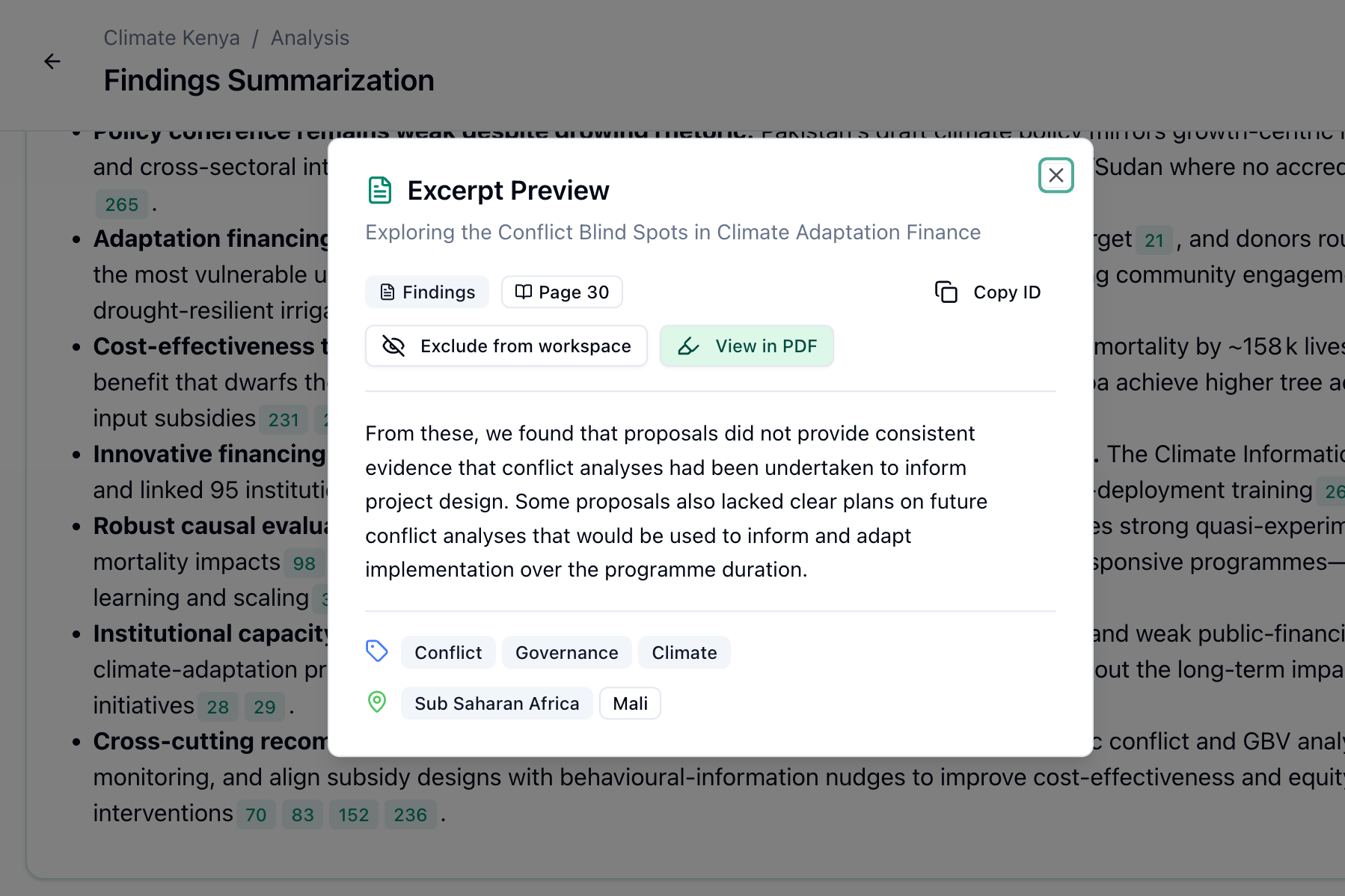
Every finding traces back to its exact source
A synthesised claim traces to the smart chunks that support it. Each chunk traces to a section in a source document. The section maps to exact page and line references. Click through to the original PDF with the passage highlighted.
In evaluation contexts — where findings inform policy and funding — unsourced claims aren't acceptable. Traceability is what makes AI-generated synthesis verifiable, and user testing confirmed it is the mechanism that earns trust.
- Inline citations on both structured analyses and chat
- Page- and line-level references on every excerpt
- Click-through to the highlighted source passage
Findings → Sustainability · pp. 45–47 · lines 1203–1267
Open the original PDF with the passage highlighted in context.
In the product, every excerpt carries its provenance — preview the source, then open the original PDF with the exact passage highlighted.

How does AI power EvalExplorer?
Learn which models we use for extraction and synthesis, how source data flows through the system, and how we address evidence fidelity — from verbatim quotation to publication-bias disclaimers.
Roadmap
The pipeline is stable, the analysis layer is operational, and both have been used by evaluation experts and external partners for real analytical work.
The corpus & what's working
The Evaluation Gap Map corpus, cleaned of duplicates, stubs and presentation-style documents. A side benefit: these evaluations are now more accessible than before the project began.
OCR parsing plus AI classification, incurred once. The saving comes at analysis time, when queries receive only focused, pre-extracted content.
Keyword + semantic retrieval, role-based sharing, exportable and publishable analyses — all in active use.
What comes next
Measuring extraction recall and synthesis fidelity at scale with LLM-as-judge evaluation, calibrated against human review — moving from “users spot errors” to a known, falling error rate.
Targeting high-value entry points — business cases, portfolio strategy reviews, programme design — plus a pipeline to auto-ingest newly published evaluations.
Conversations with evaluation teams in multi-lateral organisations on shared taxonomy standards and interoperable extraction pipelines.
About EvalExplorer
EvalExplorer was initiated by the FCDO Evaluation team, using an Evaluation Gap Map of ~1,500 FCDO evaluations as its validation corpus. The techniques scale to 200,000+ evaluations worldwide and are designed to transfer directly to other bilateral and multilateral evaluation offices.
It is built by Baobab Tech as part of a pilot from the Frontier Tech Hub, funded by the UK Government's FCDO.
Enquiries
- Rachel Lineham (FCDO) — Rachel.Lineham@fcdo.gov.uk
- Olivier Mills (Baobab Tech | Frontier Tech Hub) — olivier@baobabtech.ai
- Nick Moore (DT-Global | Frontier Tech Hub) — nick.moore@dt-global.com